计算机视觉导论
WH 老师上课强调的 insights
lecture 5#
1 MLP#
MLP 的出现:因为传统的线性模型表达能力不足 Through many non-linear layers, transform a linear nonseparable problem to linear separable at the last layer
2 Conv#
卷积的参数多少 ,其中 是输入通道数, 是输出通道数 CNN 是 sparse connection,MLP 是 dense connection FC 是 CNN 的超集,表达能力更强 Parameter Sharing = Equivariance with Translation
lecture 6#
1 data processing#
减去均值和方差应该是对于同一个 pixel 的不同图片,而非同一图片的全部 pixel
2 Weight Initialization#
Xavier Initialization: ,即标准正态化后除以 He initialization: ,即标准正态化后除以 ,因为 relu 会直接减少一半的神经元输入
3 SGD#
- 可能会碰到鞍点(saddle point)
- 可能在不同方向上 loss 降低的速度不同 其中之一的解决办法是 Momentum
4 learning rate#
epoch是所有数据过一遍 iterations = epoch_size / batch_size
5 Batch Normalization#
在 train 和 test 的时候不一样 解决了 covariance shift 的问题 / 使得 loss curve 更平滑 存在的问题: train 和 test 的时候分布不同 batch_size较小时,batch_norm的效果不好,可以考虑使用 group norm
Lecture 7#
1 He initiation#
针对 RelU 设计:乘上 每层分布不变,没有 covariance shift,但是只在初始状态下控制住了,后续 gradient 变化需要用 normalization 来控制 Batch norm 把输入限制为正态分布,使得分布更加平稳
2 Residual link#
Use network layers to fit a residual mapping instead of directly trying to fit a desired underlying mapping 使得 loss 从深层的高度 chaotic 变得更加 convex 和光滑
3 Data augmentation#
DA 的幅度不能太大,不能丢失图片中的核心信息
4 Regularization#
添加权重衰减项
5 Batch norm 也可以降低 overfitting#
因为可以限制模型的表达能力 但是在最后一层不会加 Batch norm,因为此时不认为其应该满足高斯分布
6 Softmax#
默认 当 ,
7 KL Divergence#
不满足距离的三角不等式 ,等于号取到当且仅当 随机初始化时 类别数的对数
Lecture 8#
1 * 1 conv 不等于 FC,一般用于最后修饰
1 bottleneck#
使用 bottleneck 来提高计算效率,即使用 ,来代替原来的两个 ,瓶颈的好处在于筛选掉不重要的信息
2 mobilenet#
3 Unet#
- bootleneck
- Large receptive field and provides global context
- Get rid of of redundant redundant information
- Lower the computation cost
- Skip link:
- Assist final segmentation
- Avoid memorization
4 Evaluation#
lecture 9#
- explicit: 显式地提供 3D 信息,包括点云图,mesh,voxel
- implicit: 隐式表达 3D 信息,Signed Distance Function等 aperture 的大小存在 trade-off:
- 大 aperture:明亮但是很模糊
- 小 aperture:清晰但是亮度低 解决办法:加透镜
1 perspective(projective) camera#
Camera intrinsics(5个自由度):
内参是解决相机坐标系的问题,外参是解决从相机坐标系到世界坐标系的问题 正交变换包括含镜像和不含镜像的旋转,都保长度保角度
为什么投影变换出现近大远小:因为除以了距离坐标
2 weak projective camera#
没有近大远小,上帝视角,距离非常远
3 正交投影#
保长度 好处是测量物体的高度
4 相机校准(calibration)#
一共 11 个参数,内参五个,外参 6 个,至少需要 6 组对应点,因为 1 组点坐标有两个,实际中我们会选择多组点选取能量最低的办法 为什么要选择三个棋盘,因为 K 实际上决定的是Field of View,即只能确定张角而不能确定距离,只有不在一个平面上的数据(可以是两个平行的平面)才能确定所有结果
5 深度图#
,1记录的是 z-depth 而非 v-depth,深度图只是 2.5D,因为如果计算真实世界中的距离还需要用到相机的内参 K
lecture 10#
1 stereo sensors#
disparity maps:
Advantages:
- Robust to the illumination of direct sunlight
- Low implementation cost Disadvantage:
- Finding correspondences correspondences along and is hard and erroneous
2 structure light#
主动投射,使用的是红外光,缺陷是在室外用不了,因为太阳光的红外光更加强烈,也解决不了镜面问题
3 Voxel#
H×W×D
- Can be indexed Can be indexed
- An expensive expensive geometry geometry representation representation
- Not a surface surface representation representation
- Where is the surface? the surface?
- How to upsample?
4 Mesh#
用三角形(最通用)线性逼近 3D 物体的表面
5 point cloud#
点云是一个稀疏的三维表示方法,点云中每个点都有一个坐标,不可看作是一个 的向量,因为点的顺序关系实际上不重要 点云的问题:分不清边缘和表面在哪里,因为点云只是在表面上的一种采样,采样过程包括两次随机,首先是随机选择三角形,然后在三角形内部随机选择
5.1 FPS#
实际上是一个 NP 问题,计算实在困难
5.2 Iterative Furthest Point Sampling#
可以先选择 K 个点,然后依次添加进离这些点最远的点
5.3 计算点云之间的距离#
- Chamfer distance We define the Chamfer distance between as: 对采样不敏感,因为不要求一一对应
- Earth Mover’s distance Consider of equal size . The EMD between and is defined as: where is a bijection.对采样敏感,因为总要求一一对应
5.4 点云的深度学习#
Deep net needs to be invariant to N! permutations
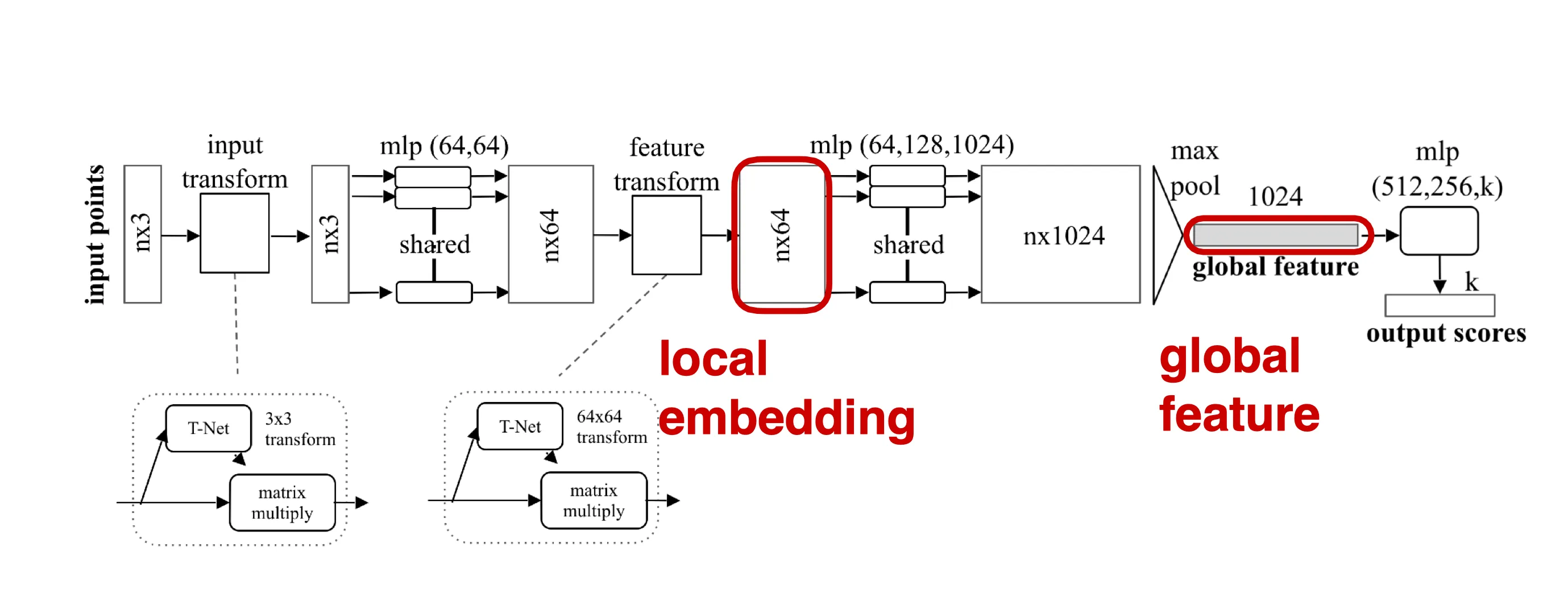 pointnet的缺陷:只能提取到全局特征,不能提取局部特征
pointnet++:Recursively apply pointnet at local regions.
pointnet的缺陷:只能提取到全局特征,不能提取局部特征
pointnet++:Recursively apply pointnet at local regions.
Lecture 11#
1 PointNet ++#
一般而言不如 3D conv 的表达能力强,因为 PointNet++ 对于位置不敏感,各向同性,想要达到相同的效果要使用 MLP field Voxelization 会造成信息损失 3D conv 计算量太大,所以使用 sparse conv,只有表面的 voxel 记为 1,只计算有数的部分,天然适合处理大批量的数据,广泛应用于工业,对于信息的损失,可以存储一个平均值以作为全局信息
2 RNN#
功能:
- 学习序列数据的特征
- 生成序列数据 W 的梯度计算了 次 Truncated RNN 的两个问题
- 初始隐藏层状态怎么确定
- 直接使用前面确定的 ht,forward 一直过来,bp 的时候固定前面的结果
- 但是问题是 bp 之后要从头到尾再 forward 一次
- 最多只见过 步之前的状态,不能看到更远的状态 也可以双向 RNN,但是代价是不能生成下文了。 Sample 的方法
- Greedy sampling:每一步都取概率最大的那个,但是导致结果是决定性的
- Weighted sampling:每一步都按照概率分布采样,但是可能采样错误结果
- Exhaustive sampling:每一步都采样所有可能的结果,但是计算量太大
- Beam search:每一步都保留前 个最优的结果,下一步再从这 个结果中继续采样 Receptive field:RNN 的每个节点都可以看到之前的所有节点 提升 RNN 容量:使用 multilayer RNN,单向变双向,但是都不解决梯度消失的问题 如果减少非线性层,则会根据权重参数的奇异值决定最终是梯度消失还是梯度爆炸 解决梯度爆炸的办法:gradient clipping,只保留方向,不改变大小
3 LSTM#
解决 RNN long term dependency 的问题,引入记忆机制 LSTM 通过 gate 控制信息的流动(逐元素乘积)
- i:input gate,决定是否输入信息
- f:forget gate,决定是否忘记信息
- o:output gate,决定是否输出信息
- g:gate gate,决定处理多少新信息
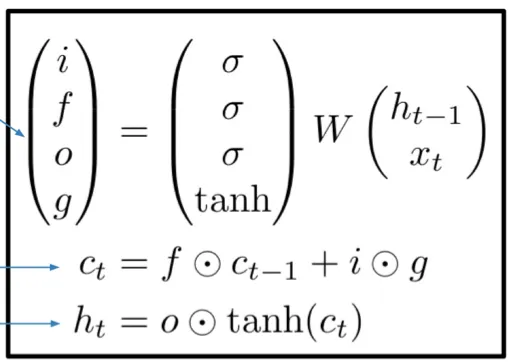
4 Seq2Seq#
问题:所有的信息只通过一个 bottleneck 传递,对于长序列来说信息太少了
- 不能使用 residual,因为序列之间不一定是一一对应的顺序 VQA的问题:图像提取的特征和问题提取的特征是分开处理的,如果要求结果准确需要图像提取出的特征完美提取所有语意信息 聚合信息的三种手段(fusion method)
- 直接加(addition)
- 拼接(concatenation)
- 乘积(element-wise multiplication) ablation study:检验融合方法的效果,替换所希望检测的组件 Image captioning:CNN 可以预训练,训练的时候可以 freeze CNN 的参数,只训练 RNN 的参数,也可以只 bp 后面的几层,freezing 之后 forward 的内存开销不变,但是 BP 会减少。
5 Attention#
Seq 2 Seq with RNN and Attention
- 所有的信息只通过一个 bottleneck 传递,对于长序列来说信息太少了
- 不能使用 residual,因为序列之间不一定是一一对应的顺序
- 可以在每计算出一个 之后和前面的所有 对齐(计算相似性 ),然后经过 softmax 得到注意力权重,将注意力权重与 相乘,得到一个加权的平均值,作为下一步的上下文信息 ,进一步得到下一个
- Attention 的优点:所有的注意权重不需要监督
Generalized 版本
- 可以看成是 query vectors (decoder RNN states) 和 data vectors(encoder RNN states) 转换成为了 output vectors (context vectors))
- 考虑余弦相似度,即
- Attention 算 softmax 的时候是逐列计算,也就是每一列内部归一化
- 整个过程是并行的,不需要序列计算
- 也可以进行 self attention,即 query 和 key 都是对一个序列进行计算
- Attention 是接受全局信息,而 CNN 只能通过加大卷积核和增加层数来获取全局信息
- Attention 对序列的位置是不敏感的,所以可以使用 positional encoding 来解决
- 为了保证序列数据不提前预知结果,可以使用 mask 来屏蔽掉未来的信息,具体操作是让 K 的对角线以下的元素为 ,然后 softmax 之后变为 0
- Multi-head self attention 内部的每个头其实也可以并行处理,一共包括四次计算QKV Projection、QKsimilarity、V 加权平均、Output Projection,2 和 3 复杂度最高,为
6 The Transformer#
不同 token 之间传播信息的方式只有 self attention,layernorm 和 mlp只在 token 内部独自变换 LLM 在最前面会有一个 Embedding Matrix,起到一个查单词表的作用
7 Vision Transformer#
把 划分成 个图像,对于每一个图像,取出 的 patch,将其展平为 维的向量,作为一个 token,最后加上位置编码
Transformer 的一些小的改变:
- Pre Norm:在每一层的前面加上 LayerNorm,将 Layernorm 加入到 residual 里面
- RMS Norm:LayerNorm 的一个变种,使用均方根来计算标准差
- SwiGLU:它结合了门控机制(Gated Linear Units, GLU) 和更有效的激活函数(SiLU),能带来更强的表示能力和更好的训练效果。
8 MOE#
关键问题是不可导
lecture 13#
1 Object Detection#
Bbox 的优良性(tight bbox):所有像素都在 bbox 内部,而且 bbox 不能更小 Loss 的选择:希望离目标点远时梯度大,离目标点近时梯度小 R-CNN
- 太慢了,提出的 ROI 太多
- 分类采用的是 SVM
- crop 出的区域如果不包含全部信息会很难处理
- R-CNN 的主要性能瓶颈是 forward CNN
所以提出了 Fast R-CNN,对特征空间操作而非直接处理 RoI Cropping features:ROI Pooling
- 使用更低分辨率的图,把框吸附到最近的格点上
- 然后把框分割,然后对每个区域做 maxpooling
- Fast R-CNN 的主要性能瓶颈是 ROI Pooling
于是又提出了Faster R-CNN
- RPN:对于每个像素点,提出 K 个 anchor box,size 是固定的
- RPN 识别出有物体的边框,会通过监督来输出一组偏移量,使得调整后的 anchor box 更接近真实的框,对于没有物体的 anchor box,输出的 correction loss 是 0
- RPN 的输出是一个二分类的概率,和一个回归的结果;根据二分类的概率排序,筛选出前 300 个位置,共 300 K 个 anchor box 供下一步
- Faster R-CNN 有 4 个 loss,RPN 的检测 loss、RPN 的回归 loss、Fast R-CNN 的分类 loss 和 Fast R-CNN 的回归 loss FPS(Frequency per second):每秒钟多少张图片,Faster RCNN 一般是 3~5 Yolo:一阶段预测,直接从图像预测类别和框;非常快,可以达到几百 FPS,但是精度不如 Faster RCNN Faster RCNN 中的 NMS:
- 先分类
- 每种类别内部按照置信度排序
- 每次取出置信度最大的框,计算和其他框的 IoU,如果大于阈值则删除
- 直到没有框了 Faster RCNN 的训练是两阶段的网络分别训练的,不是全程可导的
AP(Average Precision):如何获得 recall 和 precision 的函数,只需要按照置信度排序,然后每增加一个预测框,计算 recall 和 precision 的变化。mAP 是不同 IoU (或者类别)条件下的平均值: 代表 IoU 大于 0.5 的 AP, 代表 IoU 大于 0.75 的 AP
2 Instance Segmentation#
使用的是 Top-Down 的方法,先检测出物体,然后对物体进行分割 Mask R-CNN:提出了 ROI Align,解决了 ROI Pooling 的问题
- 吸附的过程造成了信息损失:使用双线性插值来解决
- 否则的话会导致边缘对不齐
- 对于越高的 IOU thresh,ROI Align 的优势越明显,而且甚至还能提升 bbox 精度
Lecture 15#
1 两种生成策略#
- 显示定义并且计算出密度函数
- 使用采样的方式,直接生成数据
2 FVBN#
- 直接把图片变为序列数据,利用的是 chain rule,但是计算量太大了,而且很不符合直觉
3 VAE#
本质是一个概率的 autoencoder
-
不具有采样能力,也没有显式给出密度函数
-
输出的维数远远小于特征的维数
-
解决的办法:限制特征空间的分布,比如假设为标准正态分布
-
如果是期望的形式,为了计算密度 ,需要 ,这个不好去算,如果采用 monto carlo 的话噪声太大
-
另一种方式:从 ,于是问题就变成了计算 ,这个可以使用 Encoder 去学习
-
使得采样过程变得可导了
-
VAE 无法做到完美的图,因为重建损失和 KL 散度之间存在天然的矛盾,KL 散度要求从 x 得到的 z 分布接近正态分布,但其实不符合重构损失的定义
4 GAN#
目标函数:
其中,判别器的目标函数
生成器的目标函数
但是在实际过程中,由于生成器的任务更加复杂,因此需要做出一些改变:
GAN 最适合的任务是前景服从一个简单的分布,因此适合生成人脸和室内 Mode collapse:生成器只生成一个模式的样本,判别器无法区分真假样本 使用 FID :比较真实图像和生成图像的均值和协方差的 距离
5 Diffusion Model#
还是回到了 VAE 的思想,找密度函数,但是没有简单假设高斯分布,使用了 hierarchical VAE 的方式来生成数据,来回加噪降噪