Lecture 5#
1 Grasping#
位置和方向
- 4-DoF grasp 也被称为 top-down grasp;只有一个方向,即上下动
- 主要学习 6-DoF grasp,位置和方向都是 3 D
关节活动度(手指自由度)
- 平行夹爪:1 个自由度,二指夹爪看起来两个手指,但实际上只有一个自由度
- 在夹东西的时候常常是一把抓到死,即加上最大负载
- 灵巧手:最多可达 22 个自由度
6-DoF 怎么得到
- 对于已知物品(labeled):一种方法是直接给出物体的 3 D 坐标加 3 D 旋转,然后从世界坐标系转移到机械臂坐标系
- 对于未知物品(unknown):根据点云估计,泛化能力更强
但是这两种方法都是开环策略,即 control 与 grasp 分开,如果物品移动或已经碰撞到了则无法处理; 与之相对的是闭环策略,可以处理各种干扰,但是基本都需要用到大模型,可解释性不强(实际工作常常不容许半点差错,且干扰不那么多)
2 6D Estimation#
物体首先得是刚体,然后要确定他的标架
- 为了确定物体的 6D 坐标,在相机内参确定时,RGB 图就足够了;
- 但是内参未知的时候,RGB 是不够的,还需要 depth(深度)得到点云
- 大部分情况下,Depth 相机获得点云就够了,RGB 不是重要的,但是对于对称性比较好的物体,RGB 是必需的。
PoseCNN
- 判断平移(translation)中心
- 先判断像素属于哪个物体类别(segmentation)
- 再让像素投票判断距离中心的方向和距离
- 使用 Hough voting layer ,综合 segmentation 和投票的结果得到最终结果(相比直接卷积出结果,这样更加鲁棒)
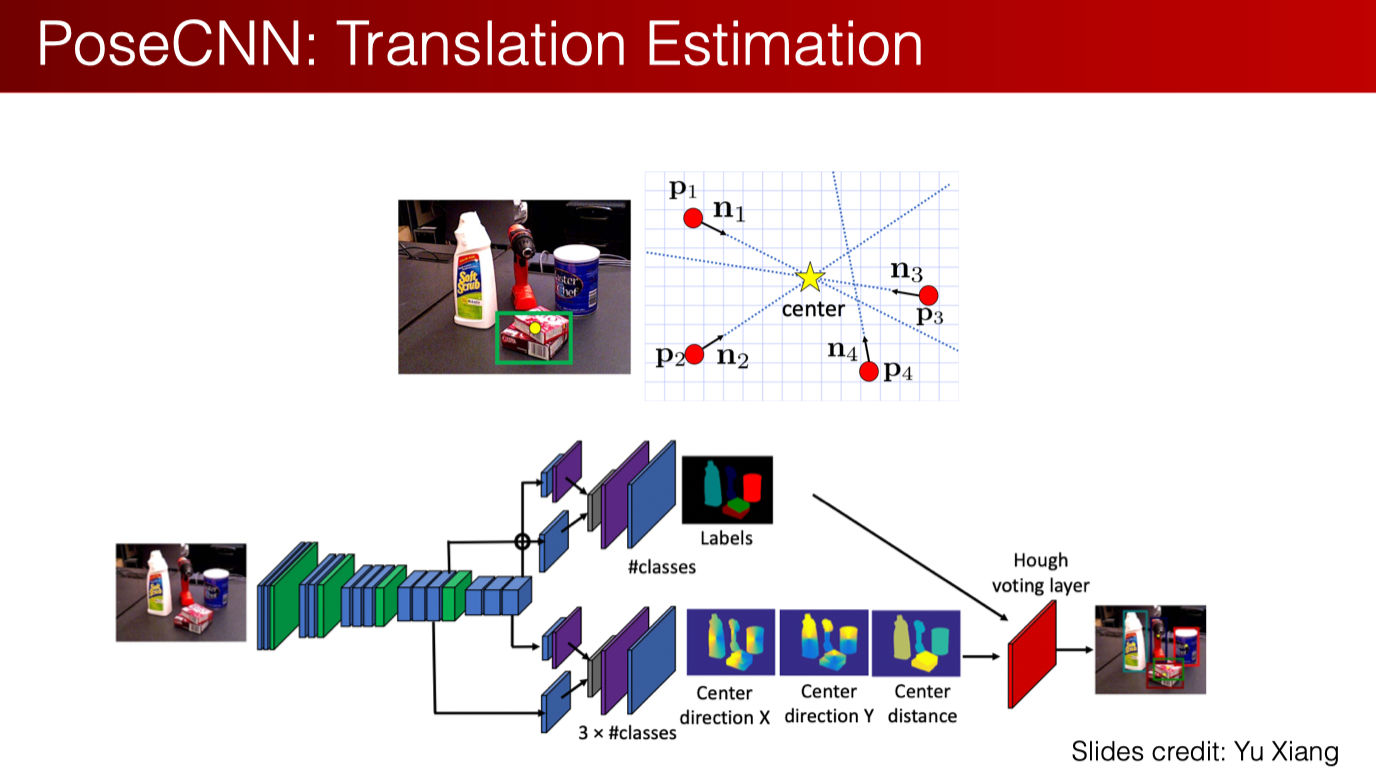
- 判断旋转
- 与判断平移类似,但是加了一步
- 对每个物品做 ROI Pool 得到 feature map,然后再塞 MLP
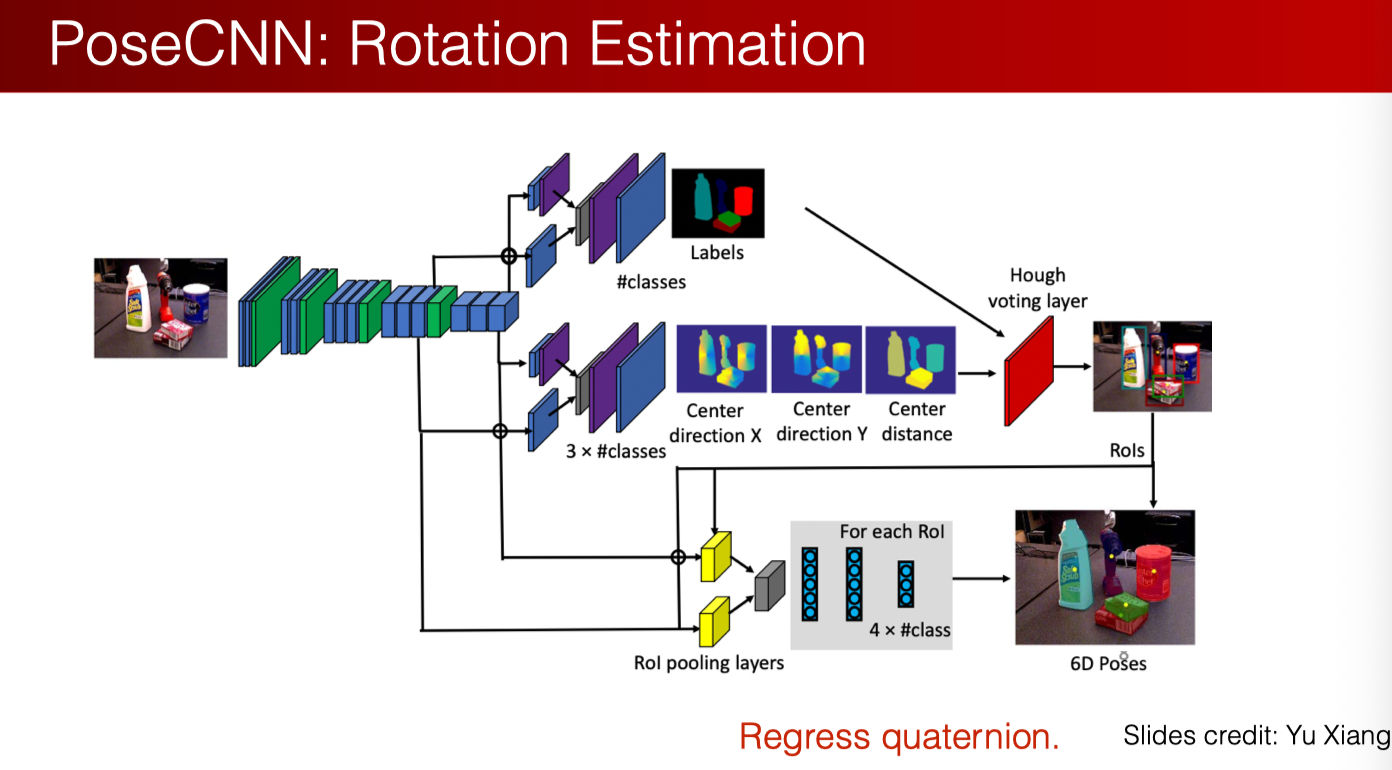
实际操作中,平移和旋转的判断精度都不那么高。
3 Iterative Closest Point (ICP)#
- 对于已知物体,由于已经知道了它的形状和坐标,我们可以 sample 出初始点云,根据算出的 和 给出估计的新点云,将其与真实目标点云比较,迭代更新
具体的比较过程是,根据当前的每个 ,去找到异动后最接近的 ,形成点对,然后分别去中心化,通过最小化中心间距离的方法确定旋转矩阵
计算 的方法是进行 SVD 分解
-
ICP 的 Loss 不可能做到 0,因为 1) sample 的点个数不一定相等 2)sample 是随机的
- 对于一一对应的东西,我们只需要做 SVD,然后得到一个旋转矩阵
- 对于没有一一对应的东西,我们把最近的点作为其估计(nearest estimation),估错了不要紧,因为可以反复迭代更新
-
ICP 不一定迭代到最好的结果,而且 ICP 速度不快,在实时性要求高的领域很难应用。但是需要 depth,对于现实要求可能不符合。
-
ICP 属于估计的 post process,本质是点云的配准;为了达到更快的收敛速度,不一定要 point-to-point,也可以 point-to-plane。
4 Rotation Regression#
旋转回归的问题:对奇异点和连续性敏感 对于旋转的判断,其目标函数可以选取 quaternion 的 L2 Loss,但是对神经网络这种连续函数,不连续点会出现很大误差。 可以证明在 以下的空间不存在到 连续的双射
- 所以可以用 6D 预测,直接看前两列向量,然后施密特正交化。
- 可以用 维空间来预测,对其进行 SVD,去掉奇异值部分,只看旋转部分
5 Pose Fitting#
可以用坐标的 Pose-Fitting:每个像素输出其对应的 3 D 坐标(有 depth 是 3 D-3 D,否则需要相机内参),然后使用 RANSAC 并 SVD
6 Render-and-Compare: FoundationPose as an Example#
2D 版本的 ICP。先用基础模型粗略估计模型的坐标,然后渲染出粗略的估计,并输入下一个模块,让下一个模块猜测如何微调。 但是需要 CAD model,为了解决这个问题,我们又研究了 Category-Level 6 D Object Pose Estimation,只需要已知类别就可以泛化。
Lecture 6#
对于已知物体,可以采取从 Object pose 到 grasping pose 的办法,但是未知物体需要直接预测 grasping pose 开环策略指的是只能 motion plan 然后去抓,应对不了位置改变, 闭环策略指的是循环操作,可以应对 object 位置的改变
1 Grasp Detection#
detect 的目标:6D(R 和 T)+1D(开合的宽度) 如何选取 input?我们很少直接使用 image(RGB) 作为预测,而是使用 3D 特征,比如多方向图片得到 Voxel。但是 Voxel 的精度导致太昂贵了,我们一般选取物体表面的点云来进行预测。
抓取效果
- success rate:越高越好
- Percent cleared:越高越好
- Planning time:越低越好
1.1 GS-Net#
GS-Net:一个常用的 Grasp detection 网络 voxel-based 的网络设计较简单:先预测 voxel 是否是抓取中心,再输出抓取预测 点云怎么办:不能只对表面猜测,而是 where + how
- where:通过 encoder-decoder 结构学习哪些位置附近适合抓取,给出 graspness 评分,再进一步筛选得到前 M 个
- graspness 分为点级别的 graspness 和 view-level 的 graspness,前者是每个点的评分,后者是每个方向抓取点的评分
- how:xyz+view(视线朝向)+angle(旋转角度)+depth(插入深度)一共 7 DoF,其中每一步都是在离散得到,然后分别评分
- 为什么 GS-Net 优秀?
- 抓取对象是点云,只有几何信息,与颜色无关
- 抓取本身与物体关系不大,只看局部信息,所以好泛化
- GS-Net 本身在确定抓取 angle 时只处理附近的局部信息,不看其他无关变量
- 但是 GS-Net 离散太多了,不是很自然
1.2 条件生成模型-Conditional Grasp Generative Model for Dexterous Hand#
如果不想采用离散模型,可以考虑扩散模型,但是扩散模型也很容易包含很多无关信息,所以要做很多局部化 所以借鉴 GS-Net 的思路,也要先选点,然后考虑点附近的局部信息。
- where:这部分和 GS-Net 差不多,也是找点然后预测是否合适抓
- 使用局部特征预测 objectness 和 graspness
- how:这部分不一样,是将局部信息喂给 Diffusion 模型
- 只用第一步的局部特征,来预测 7 个参数
2 抓取数据合成#
force-closure:物理上的合成方法,其核心思想是任意微小扰动都能维持抓取状态
- 所有接触点的 wrench cone 的正组合,可以覆盖整个 wrench space。
- 其中 wrench 包括力和力矩,
- 其实就是说摩擦力可以抵消所有力
- 所谓 form-closure,指的是不靠摩擦,只用几何形状就锁住了物体
- 通常来说,successful grasp <= force-closure <= form-closure
在 GS-Net 中,合成数据的过程其实尝试了很多 下的 force closure 来训练模型,结果发现 这种小的值效果最好,抓法也更保守。
3 Camera Model#
pinhole camera
但是当光少的时候特别糊,所以我们加上透镜 透镜的特点:平行光汇聚于焦点 根据 snell 定律
3.1 内参#
其中 和 是 focal length 乘以像素的宽高, 和 是主点坐标 为了用线性变换来描述它,我们引入齐次坐标 ,则可以得到
也即 其中 就是内参矩阵 如果加点偏斜,就是
3.2 外参#
将世界坐标系下的点 转换到相机坐标系下的点 ,需要知道相机相对于世界坐标系的位置和朝向,即外参 然后
4 Hand-Eye Calibration#
- hand in eye: 机械臂上装了一个相机,在计算基座坐标系下位置时,要先从相机坐标系到机械臂末端坐标系,然后再从机械臂末端坐标系到基座坐标系
- hand to eye: 相机相对基座位置不变,可以直接从相机坐标系到基座坐标系
4.1 Hand in Eye#
为了解决这个问题,其实就是要解决 camera 到 end-effector 的坐标变换 固定住标定板的位置然后移动机械臂获取两方面数据:机械臂相对基座的位置和相机看到的标定板位置 根据前者,我们可以知道机械臂的变换 ;根据后者,我们可以计算出相机的变换 ,于是我们就可以算出但是从 到 的变换 不变,所以只需要解方程
4.2 Hand to Eye#
类似地,我们把 calibration board 放在机械臂末端,然后移动机械臂获取两方面数据:机械臂相对基座的位置和相机看到的标定板位置,但是由于标定板在机械臂末端,所以 到 的变换 是不变的,我们也可以得到类似地方程
然后再根据它得到,相机相对基座的变换